

Нейронные сети для начинающих
Изучаем нейронные сети за четыре шага
Изучаем нейронные сети за четыре шага
- Переводы , 7 августа 2016 в 23:21

В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод — это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
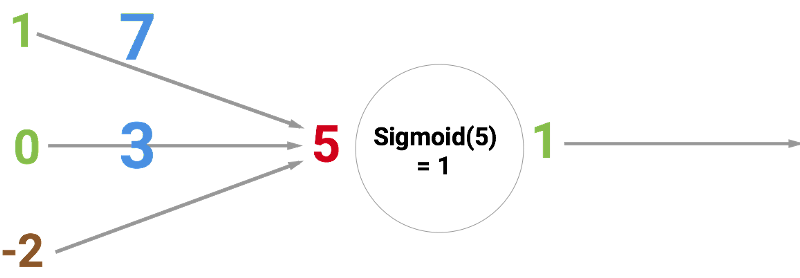
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
4 – 29 мая , онлайн, беcплатно
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это — ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть — процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Я очень рекомендую посмотреть серию видео от Welch Labs для улучшения понимания процесса.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera, посвящённой нейронным сетям — она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды, так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса, поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть здесь.
Вам необязательно делать это самим, поскольку тут требуются специальные знания — главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется методом обратного распространения ошибки.
Вкратце: вы оцениваете, насколько сеть ошиблась, и изменяете вес входных значений (синие числа на первой картинке).
Процесс идёт от конца к началу, так как мы начинаем с конца сети (смотрим, насколько отклоняется от истины догадка сети) и двигаемся назад, изменяя по пути веса, пока не дойдём до ввода. Для вычисления всего этого вручную потребуются знания матанализа. Khan Academy предоставляет хорошие курсы по матанализу, но я изучал его в университете. Также можно не заморачиваться и воспользоваться библиотеками, которые посчитают весь матан за вас.

Скриншот из руководства Мэтта Мазура по методу обратного распространения ошибки.
Вот три источника, которые помогли мне разобраться в этом методе:
В процессе прочтения первых двух статей вам обязательно нужно кодить самим, это поможет вам в дальнейшем. Да и вообще, в нейронных сетях нельзя как следует разобраться, если пренебречь практикой. Третья статья тоже классная, но это скорее энциклопедия, поскольку она размером с целую книгу. Она содержит подробные объяснения всех важных принципов работы нейронных сетей. Эти статьи также помогут вам изучить такие понятия, как функция стоимости и градиентный спуск.
Шаг 4. Создание своей нейронной сети
При прочтении различных статей и руководств вы так или иначе будете писать маленькие нейронные сети. Рекомендую именно так и делать, поскольку это — очень эффективный метод обучения.
Ещё одной полезной статьёй оказалась A Neural Network in 11 lines of Python от IAmTrask. В ней содержится удивительное количество знаний, сжатых до 11 строк кода.

Скриншот руководства от IAmTrask
После прочтения этой статьи вам следует написать реализацию всех примеров самостоятельно. Это поможет вам закрыть дыры в знаниях, а когда у вас получится, вы почувствуете, будто обрели суперсилу.
Поскольку в примерах частенько встречаются реализации, использующие векторные вычисления, я рекомендую пройти курс по линейной алгебре от Coursera.
После этого можно ознакомиться с руководством Wild ML от Denny Britz, в котором разбираются нейронные сети посложнее.

Скриншот из руководства WildML
Теперь вы можете попробовать написать свою собственную нейронную сеть или поэкспериментировать с уже написанными. Очень забавно найти интересующий вас набор данных и проверить различные предположения при помощи ваших сетей.
Для поиска хороших наборов данных можете посетить мой сайт Datasets.co и выбрать там подходящий.
Так или иначе, теперь вам лучше начать свои эксперименты, чем слушать мои советы. Лично я сейчас изучаю Python-библиотеки для программирования нейронных сетей, такие как Theano, Lasagne и nolearn.
Нейросети. Самый полный гайд. Часть 1 для чего нужны нейросети
Всем привет, сегодня мы с вами поговорим о такой области программирования как нейросети. Для чего они нужны, когда их придумали, ну и конечно как они работают. Статья получилась такая большая, что я решил разбить её на три части. В этой части описано для чего нужны нейросети, а если интересно узнать чем всё закончится, или посмотрите ролик, или дождитесь второй и третей части. Вот в ролике всё целиком.
Первая часть. Для чего нужны нейросети.
Для того что бы понять что же такое нейросети и для чего они нужны, нам стоит вообще понять суть решения задач при помощи электронно-вычислительных машин. В общем случае любая задача решается на компьютере в 6 этапов:
1. Постановка задачи. В ходе этого этапа происходит подготовка к решению, а так же запись всех исходных данных и требуемого результата.
2. Формализация. Т.е. запись на каком либо формальном языке процесса превращения исходных данных в результат. Чаще всего это язык математики или формальной логики.
3. Создание алгоритма.
4. Запись алгоритма, на каком либо компьютерном языке.
5. Тестирование и отладка.
6. Проведение расчетов и анализ результатов.
Как видим, три первых пункта вообще никоим образом не относятся к компьютеру. А 6-й пункт уже относиться не столько к программированию, сколько к практике. Теперь и вы наглядно можете видеть, что большая часть программирования – это не столько нажимание на кнопочки, сколько размышления над тем или иным алгоритмом, которые довольно часто сливаются в размышления над смыслом жизни. Так же понятно, что удачные алгоритмы можно создавать и вовсе не знаю ни одного языка программирования. На практике это означает что человеку, который освоил создание программ на одном языке программирования, будет гораздо проще освоить другой язык, чем человеку, который вообще не сведущ в программировании.
Весь этот список, более менее понятен любому человеку. Кроме, быть может, третьего пункта. Если не знать что такое алгоритм нельзя и понять что требуется. Хотя всем нам на интуитивном уровне ясно, что это, но даже немногие программисты знают, что в информатике у этого слова есть довольно чёткое определение.
Алгоритм – это строго детерминированная последовательность действий, описывающая процесс преобразования объекта из начального состояния в конечное, записанная с помощью понятных исполнителю команд. Думаю что только слово «детерминированная», может вызвать вопросы. Это слово означает что алгоритм должен состоять из самых простых и однозначных действий, который способен выполнить исполнитель.
Пример: «сделай мне бутер», это не детерминированная команда.
«Отрежь хлеб», «отрежь колбасу», «положи колбасу на хлеб» – уже гораздо более детерминированные команды. Ведь согласитесь, бутер можно сделать и без колбасы или с колбасой и маслом.
Так же в жизни очень многие тру-программисты вовсе не записывают алгоритм отдельно, постоянно держа его целиком у себя в голове. Это привычка о двух концах. С одной стороны она экономит время, с другой стороны из-за неё происходят порой самые глупые и труднонаходимые ошибки. Но в любом случае не записывание алгоритма на бумаге, не означает не создание его в голове. Прежде чем начать клацать на кнопочки, любой человек обязательно создаст алгоритм работы программы у себя в голове.
Кстати для записи алгоритмов есть специальный язык – блок схемы. Большинство из тех кто изучал программирование в учебном заведении его узнает. Остальные, даже вполне успешные программисты, понятия не имеют что это такое.
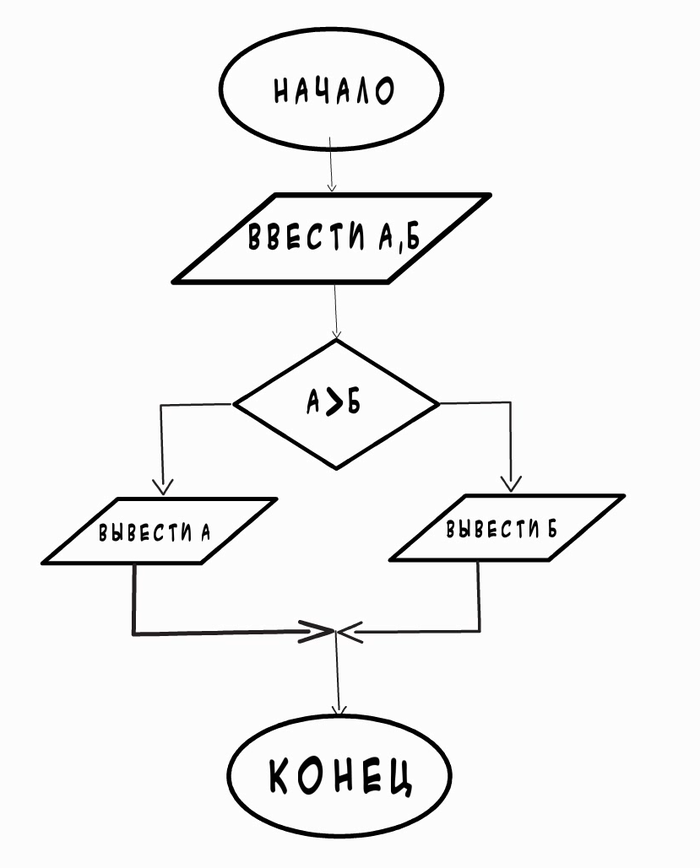
Теперь зная об алгоритмах, мы с вами должны ответить для себя на такой вопрос. Можно ли при помощи алгоритмов описать любую последовательность действий, которая не противоречит законам физики и математики. Пример: сможем ли мы написать алгоритм движения боевого шагающего паука-робота, если до этого были очень успешны в написании других алгоритмов. Ответ – да. Если выполнены два пункта из списка выше, то и третий не должен создать проблем. Давайте сейчас вместе попытаемся приступить к решению данной задачи. И всё по науке, по пунктам.
1. Исходные данные и результат.
Исходные данные: Робот – 1 штука. Ноги – 6 штук. Суставы на ногах – 3 штуки на каждой. Степени свободы у каждого сустава – по одной. Начальные координаты каждой ноги и сустава. Начальные углы в суставах робота. Начальная координата центра робота.
Результат: робот сместился на Х метров в указанном направлении.
На этом этапе мы должны чётенько расписать опираясь на законы Ньютона куда и когда послать усилие на сервопривод чтобы нога передвинулась в необходимое нам место.
3. Написание Алгоритма.
Теперь зная, куда и когда двигаются ноги, мы должны расписать последовательность их движения, отталкиваясь от взаимного их расположения и координаты куда нам требуется попасть. Алгоритм будет громадный, с кучей разных условий, но он будет работать.
4. Превратим всё это в строчки кода.
5. Зальём в голову микрочип робота.
6. Отправим робота на прогулку.
Да, я вам не сказал что робот у нас запитан не от святого духа, а от энергии, которую вырабатывает топливный генератор. Во время его путешествия, часть топлива сгорела и масса робота стала меньше начальной отчего он потерял равновесие и упал.
Ну не беда, теперь вы знаете что в начальные данные нужно внести массу, и все вычисления переписать с учётом нового параметра и заодно внести правки в алгоритм. Ок, сделано. Снова робот отправляется на прогулку. И ему случайно отстреливают правую переднюю ногу, это же боевой робот. Средняя правая нога ждёт результата от передней. Ведь она должна шевелиться после неё. Но от неё нет результата, у нас больше НЕТ правой передней ноги. Приехали, дальше робот не пойдёт. Теперь нужно переписать алгоритм, чтобы он работал без передней правой ноги. И конечно, без передней левой, и без средней задней. И без второй фаланги задней левой. И для каждого из этих случаев нам нужен НОВЫЙ алгоритм. Пускай и не радикально другой, но всё же новый. Итого нужно написать 100500 алгоритмов, и если какой то забыли, то это всплывёт в самый неподходящий момент.
Разумеется возникла идея создать такой алгоритм который мог бы подстроится к изменениям прям на ходу. Ведь паук в природе как то передвигается если ему оторвать ногу. Это и было зарождением нейросетей. По сути нейросеть – это такой алгоритм, который не нужно записывать в привычном понимании. Мы строим некую логическую конструкцию с начальными параметрами, а дальше она сама обучается, по каким-нибудь правилам, и принимает решение в каждом конкретном случае самостоятельно, исходя из старого опыта. История возникновения нейросетей отправляет нас прямиком к 1943 год, т.е. нейросети придумали сразу, как только появились ЭВМ. Но вот беда, в те времени один нейрон был размером с холодильник, а для серьёзных задач нейронов требовались сотни и даже тысячи. Почесав затылки, тогдашние программисты и инженеры сказали что мы и так всё сделаем без ваших нейросетей и отринули данную идею. Вновь к нейросетям вернулись только через 30 лет, за это время компьютеры шагнули невероятно далеко, на целых 4 поколения. В 71-м как вы помните, изобрели первый процессор. А в 75-м на этих крутейших по тем временам компам японский программист Кунихико Фукусима создал так называемый когнитрон – нейронную сеть умеющую выполнять логическую операцию «или». Вдумайтесь 30 лет от задумки да простейшей реализации.
Из вышесказанного вытекает и функция нейросетей. Они нужны тогда когда классические алгоритмы плохо справляются с задачей, или же условия задачи могут немного измениться в процессе её выполнения, что потребует новый классический алгоритм.
Примеров применения нейросетей сегодня можно привести целую кучу. Очень популярны в последнее время нейросети распознающие образы. Такие используются в автомобилях Тесла например. Одна нейросеть переводит окружающий мир в 3D модель, а другая управляет автомобилем вместо человека.
Создание искусственного интеллекта – тоже пример использования нейросетей. Голова у Яндекс Алисы, или эпловской Сири, не из классических алгоритмов состоит, а из множества нейрончиков. Именно нейросети распознают вашу речь когда вы спрашиваете что то у гугла, и делают подборку песен, которая вам скорее всего понравиться. А ещё они всё больше вытесняет работников техподдержки, заставляя нас кричать в трубку: «Я хочу поговорить с человеком!». Если честно, всего 6 лет назад когда я смотрел фильм «Элизиум: Рай не на Земле», я и представить не мог себя в ситуации когда я буду спорить с роботом, и просить его переключить на человека. Но я думаю что с подобной проблемой сталкивались уже многие. Сейчас способности ИИ, оставляют желать лучшего, но скорость развития этих гомункулов поражает. И спустя те же 6 лет, человек в тех поддержке будет такой же редкостью, как сегодня использование DVD-дисков.
Несмотря на относительную тупизну, нейросети и сегодня влияют на вашу жизнь, и быть может даже больше чем вы думаете. Именно они решают, дать вам кредит в банке или отказать, какой фильм или музыка вам может понравиться, и какую рекламу вам показать, анализируя ваш сёрфинг интернета, а быть может и подслушавшая за вами через телефон.
Нейронные сети для начинающих
Искусственные нейронные сети (ИНС) — это вычислительные системы, основанные на биологических нейронных сетях, составляющих мозг животных. 
Искусственная нейронная сеть позволяет моделировать некую нелинейную функцию с входными и выходными данными.
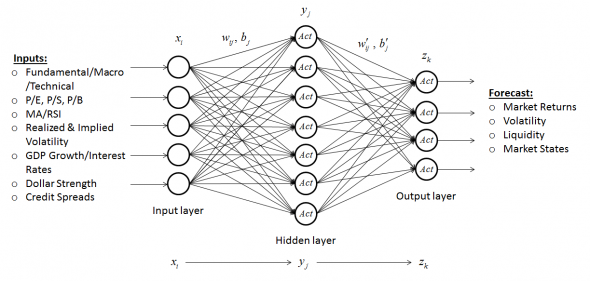
Нейронная сеть имеет:
· Входной слой, куда подаются входные параметры, ассоциирующиеся с состоянием каждого нейрона входного слоя. Например, для финансового аналитика это могут быть различные индикаторы — макроэкономические, фундаментальные, технически.
· Выходной слой, в котором вычисляются выходные параметры, ассоциирующиеся с состоянием каждого нейрона выходного слоя. Сюда поступает информация, которую мы хотели бы предсказать. Например, это может быть будущий возврат рынка в %, волатильность, ликвидность и т.д.
Нейросеть оперирует цифрами, поэтому любая входная и желаемая выходная информация должна быть оцифрована. Например, если это текст (новости), то нужно этот текст представить в виде массива цифр. Или, если мы пытаемся предсказать куда пойдёт рынок, вверх или вниз, то можно закодировать «вниз» нулём, а «вверх» единицей.
Если нейронная сеть имеет дополнительные слои между входным и выходным слоем, то они называются скрытыми, а обучение такой сети — глубоким. Дополнительные скрытые слои могут помочь нейросети определить более сложные закономерности между входными и желаемыми выходными данными.
Каждый слой связан с соседними слоями с помощью весовых коэффициентов и коэффициентов смещения. Распространение данных от предыдущего слоя к следующему осуществляется по следующему правилу: z = Act(Wy + b), где y — вектор данных на предыдущем слое, z — вектор данных на следующем слое, W — матрица весов перехода от предыдущего слоя к следующему, b — вектор коэффициентов смещения. Act — функция активации, необходимая для устранения линейности. Функций активации существует большое количество. Например, это может быть сигмойда: 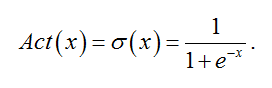
Обучение нейронной сети с учителем означает, что для заданного набора заранее известных входных и выходных данных, необходимо подобрать оптимальные коэффициенты W и b нейросети так, что квадратичная ошибка между точным выходным значением и выходным значением, полученным посредством распространения входных значений через нейронную сеть, стремилась к минимуму:
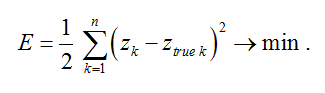
Например, вы хотите научить предсказывать по прошлой динамике цены акции и динамике индикаторов Simple Moving Average (SMA) и Relative Strength Index (RSI) будущее изменение цены этой акции в процентах. Мы формируем данные для обучения — для каждого исторического момента времени берём данные по индикаторам и цене акции. Это будут входные данные X для нейронной сети. И для каждого исторического момента времени берём будущее изменение цены акции (мы его точно знаем, т.к. речь идёт об исторических данных). Это будут выходные данные Y нейронной сети, которые мы хотим, чтобы нейросеть научилась предсказывать. Для этих данных X и Y и будут подбираться коэффициенты W и b.
Поиск оптимальных коэффициентов производится методом градиентного спуска с использованием метода обратного распространения ошибки: 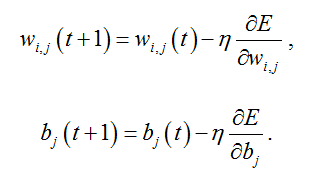
где градиент функционала E для W выражается следующим образом: 
И аналогично для b: 
Хочу привести такую аналогию обучения нейронной сети для трейдеров. Надеюсь, она будет вам более понятной, если нет понимания математического аппарата. Представьте, что вы придумали стратегию, у которой очень и очень много параметров. Естественно, вам хотелось бы подобрать наиболее оптимальные параметры для стратегии (как коэффициенты W и b в случае нейросети). Что значит оптимальные? Такие, чтобы максимизировали прибыль или минимизировали просадку или максимизировали коэффициент Шарпа — смотря какой критерий выберете. Далее вы начинаете перебирать эти параметры (обучать, в случае нейронной сети). Можно перебирать с помощью «грубой силы» — т.е. перебирать все возможные комбинации параметров. Но если таких параметров очень много, то вам просто не хватит вычислительной мощности вашей машины и перебор займёт много времени. Поэтому придумано достаточно много оптимизационных алгоритмов. Например, метод градиентного спуска и его вариации или генетический алгоритм, чтобы производить поиск оптимальных параметров быстрее, жертвуя точностью.
У нейронной сети могут быть те же проблемы, которые возникают при оптимизации стратегий. Главная из них — переобучение. Когда всё работает очень хорошо на прошлых данных и плохо работает на данных out-of-sample. Про то, как минимизировать риск переобучения и правильно тестировать стратегии, думаю, поговорим в следующей статье.
В качестве примера, я создал полносвязанную нейронную сеть из входного, выходного и двух скрытых слоёв. Во входном слое я сгенерировал 45 нейронов — туда будем подавать дневные изменения цен S&P 500 за последние 15 дней, значение индикатора SMA за последние 15 дней и значение индикатора RSI за последние 15 дней. Выходной слой состоит из 1 нейрона и будет хранить предсказанное процентное изменение S&P 500 на следующий день. Скрытые слои содержат по 512 нейронов. Обучим нейронную сеть на данных с октября 2019 года по июнь 2019 г. и проверим точность обученной нейронной сети на данных с июля 2019 года по сентябрь 2019 г.
У меня получились следующие результаты. На графике ниже показан дневной возврат S&P 500 c октября 2019 года по июнь 2019 г. (тренировочные данные) — синяя кривая. Если кривая выше нуля, то это значит, что S&P 500 в этот день вырос. Если ниже — упал. 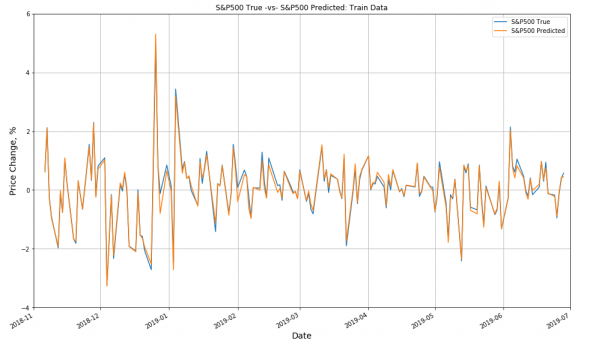
Также я наложил оранжевую кривую на синюю. Это предсказанный нейросетью возврат рынка. По прошлой динамике S&P 500, SMA и RSI за последние 15 дней для каждого исторического момента. Точность предсказания (вырастет S&P 500 на следующий день или упадёт) составила 93%. Но это тренировочные данные. На тестовых данных с июля 2019 г. по сентябрь 2019 г. результаты получились намного скромнее: 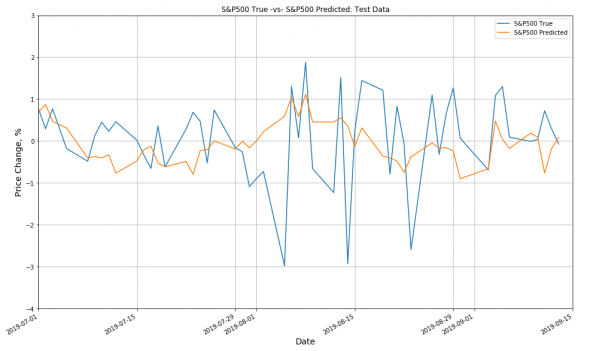
Точность предсказания составила лишь 49%. Нейронная сеть явно переобучена. Но, учитывая простоту модели, вряд ли можно было ожидать более приемлемый результат.
ЗАКЛЮЧЕНИЕ:
1. Искусственная нейронная сеть — это «чёрный ящик», который можно обучить по заданным входным данным выдавать нужные нам выходные данные (например, прогноз чего-либо).
2. С точки зрения трейдинга на вход нейронной сети можно подать различные индикаторы — макроэкономические, фундаментальные и технически и обучить её предсказывать будущий возврат рынка, волатильность, ликвидность, состояния и т.д.
3. Нейронная сеть, как и любая алгоритмическая стратегия трейдинга, может быть переобучена (переоптимизирована). За этим нужно следить как минимум путём деления данных на тренировочные и тестовые.
Как обучить свою первую нейросеть
Главным трендом последних нескольких лет, безусловно, можно назвать нейросети, машинное обучение и все, что с ними связано. И на то есть серьезные причины, ведь в последнее время нейронные сети удивляют своими умениями. Мало того, что нейросеть уже может нарисовать портреты людей по одним только их голосам и «оживлять» портреты Достоевского и Мэрилин Монро, так она еще способна показать, как вы будете выглядеть через 20, 30 и даже 50 лет! Конечно, все это делает не одна нейросеть — в мире существует множество подобных разработок, которыми занимаются специалисты по Data Science.

Научиться обучать нейросети гораздо проще, чем кажется
Как появились нейросети
Все началось с попыток ученых приблизить принцип работы компьютера к образу мышления человека. На это ушли десятилетия исследований, и в итоге это стало возможным при помощи нейросетей — компьютерных систем, собранных из сотен, тысяч или миллионов искусственных клеток мозга, которые способны обучаться и действовать по принципу, чрезвычайно похожему на то, как работает мозг человека.
Конечно, нельзя говорить, что нейронная сеть — это точная искусственная копия мозга. Важно отметить, что нейросеть — это прежде всего компьютерная симуляция: такие сети созданы посредством программирования обычных компьютеров, в которых традиционным образом работают обычные транзисторы, объединенные в логические связи.

Как нейросеть генерирует новые фото
Из чего состоят нейросети
Обычная искусственная нейронная сеть состоит из десятков, сотен, тысяч или даже миллионов искусственных нейронов. Их называют блоками — они выстроены в слои, где каждый блок соединен с соседним. Есть блоки ввода, с помощью которых нейросеть получает информацию, и блоки вывода — они как раз отвечают за результат обработки.
Когда сеть обучается, образцы информации «скармливают» ей через блоки ввода, а затем добираются до блоков вывода. Например, можно показать нейросети огромное количество фотографий стульев и столов, максимально доступно объяснив ей разницу между этими предметами мебели. А затем попросить ее распознать объект на картинке, где изображен шкаф. В зависимости от того, насколько эффективно вы обучили нейросеть, она попытается отнести увиденное к категории, основываясь на имеющемся опыте.
Как обучают нейросети
Нейросети обучаются «методом обратного распространения ошибки». С его помощью удается сопоставить выходные данные с теми данными, которые ожидалось получить, и использовать различия между этими данными для внесения изменения в связи между блоками, занятыми в сети. Чем больше обучается нейронная сеть, тем быстрее получается свести до нуля разницу между желаемым и реальным результатами.
Одна из моделей машинного обучения
Как только нейросеть прошла обучение с использованием достаточного количества примеров, она достигает стадии, когда вы можете предоставить ей совершенно новый набор вводных данных, которого она никогда не видела, и следить за ее реакцией.
Области использования нейросетей ничем не ограничены. Так, они могут осуществлять поиск по картинке или выступать в роли голосового ассистента — та же Алиса уже максимально приблизилась по своему поведению к реальному человеку. Или высчитывать вероятность заболеваний, находить опухоли на снимках, бороться с мошенниками и так далее.
Можно ли самому научиться работать с нейросетями
Раньше такая возможность предоставлялась только ученым, поскольку наработки в области нейронных сетей и машинного обучения были слишком «сырыми». Но сейчас любая технологическая компания генерирует огромный объем данных, который нужно обрабатывать, чтобы затем на его основе оптимизировать бизнес и проанализировать перспективы. Для этого и других задач, связанных с нейросетями и машинным обучением, нужны специалисты по Data Science.
Как им стать? Самостоятельно сделать это почти невозможно. Это серьезная специализация, которая требует взаимодействия с теми, кто уже работает в данной области. Поэтому школа данных SkillFactory открывает новый набор на полный курс по Data Science. В рамках курса профессионалы отрасли, в том числе сотрудники Яндекса и NVIDIA, обучают тонкостям работы, о которых не пишут в учебниках.

Все преподаватели — специалисты в области Data Science
С помощью этого курса можно освоить науку по работе с данными с нуля, даже если вы ни разу в жизни не занимались программированием. Он позволяет получить все навыки, необходимые специалисту по Data Science — от программирования на Python, в том числе углубленного изучения Pandas для анализа данных, до машинного обучения, глубинного обучения и исследования данных. Курс состоит примерно из 20% теории и 80% практики, поскольку только на реальных примерах возможность стать профи в этой области.

Программа курса рассчитана на 12 месяцев
В процессе обучения вы сможете создавать свои проекты в сфере распознавания изображений, NLP и скоринга. Вместе с преподавателями и менторами разберетесь в деталях работы и получите необходимую обратную связь. Кроме того, в SkillFactory помогают с трудоустройством и рекомендуют к стажировке в крупных компаниях. Например, выпускники получают возможность работать в «Альфа-Банке», Bayer, Henkel, «Сбербанке» и других ведущих организациях.

По окончании обучения выдается сертификат
Присоединяйтесь к курсу уже сейчас и получите скидку 15% на обучение по промокоду Hi-news (действует до 15.02.2020). Набор совсем скоро закончится, поэтому времени на раздумья не так много.

На карантине многие начали осваивать новые профессии. Большинство офлайн-бизнесов вряд ли переживут пандемию, и нет ничего удивительного в том, что люди стали активно интересоваться программированием, машинным обучением и другими специальностями, которые не только будут наиболее востребованы в ближайшие несколько лет, но и также подразумевают работу онлайн из любой точки мира. Например, количество вакансий по профессии […]

Нейросети уже дошли до такого уровня, что могут обыгрывать в шахматы или го профессиональных игроков. С помощью машинного обучения ученые обучают нейросеть, создают реалистичный симулятор, а затем реальный игрок пытается сразиться с мощью алгоритма на компьютере. Однако пока никому не приходило в голову использовать нейросети в активном спорте — например, при игре в настольный теннис. […]

Во время пандемии коронавируса социальное дистанцирование оказалось очень эффективной мерой для замедления распространения заболевания. Но в то время, как миллионы людей остаются дома, чтобы совместными усилиями победить опасную инфекцию, многим сотрудникам в пищевой, добывающей, фармацевтической и других промышленностях все еще приходится ходить на работу каждый день. От них зависит, чтобы к вам завтра приехал курьер […]
Изучаем нейронные сети: как создать нейросеть за 4 шага?

В этой статье вы получите ряд разъяснений и рекомендаций, которые пригодятся вам при создании нейронной сети. Также будут предоставлены полезные ссылки для самостоятельного изучения. Что же, не будем терять времени!
Шаг 1. Поговорим о нейронах и методах прямого распространения
Прежде чем начать разговор о нейронных сетях, нужно сначала разобраться с тем, что такое один нейрон. Здесь всё достаточно просто: нейрон принимает несколько значений, а возвращает только одно, стало быть, он похож на функцию.
Для наилучшего понимания давайте посмотрим на картинку ниже. Круг — это искусственный нейрон. Он получает 5, а возвращает 1. Под вводом понимается сумма трёх синапсов, соединённых с нейроном (это три стрелки слева).
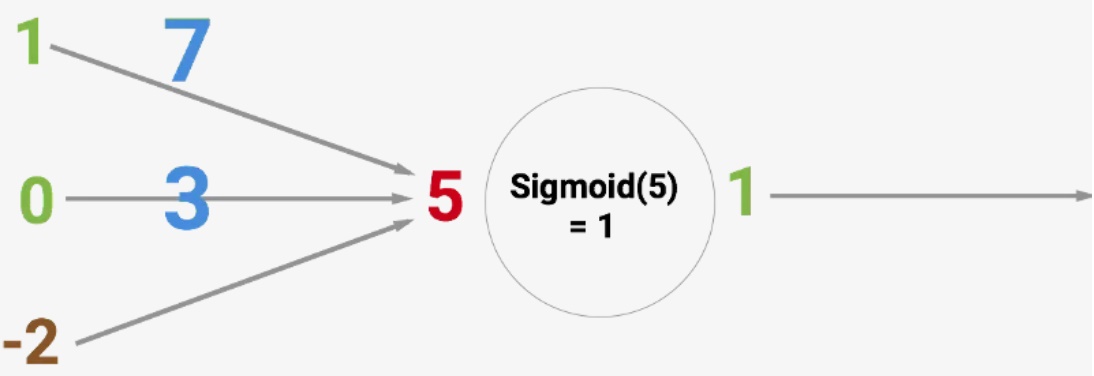 В левой части у нас находятся два входных значения (выделены зелёным цветом) и одно смещение (выделено коричневым цветом).
В левой части у нас находятся два входных значения (выделены зелёным цветом) и одно смещение (выделено коричневым цветом).
При этом входные данные могут быть численными представлениями 2-х различных свойств. К примеру, когда создаёшь спам-фильтр, они могут означать наличие больше чем одного слова, написанного прописными буквами, и наличие слова «Виагра».
Также следует понимать, что входные значения умножаются на собственные так называемые «веса» — в нашем случае это 7 и 3 (выделены синим).
Далее полученные значения складываются со смещением, и получается число 5, которое у нас выделено красным. Это и есть ввод искусственного нейрона.
 Идём дальше. Нейрон выполняет вычисление, выдавая выходное значение. Мы получили 1, так как именно единице равно округлённое значение сигмоиды в точке 5. Если, опять же, вспомнить про спам-фильтр, то факт вывода единицы означал бы, что текст был помечен нейроном в качестве спама.
Идём дальше. Нейрон выполняет вычисление, выдавая выходное значение. Мы получили 1, так как именно единице равно округлённое значение сигмоиды в точке 5. Если, опять же, вспомнить про спам-фильтр, то факт вывода единицы означал бы, что текст был помечен нейроном в качестве спама.
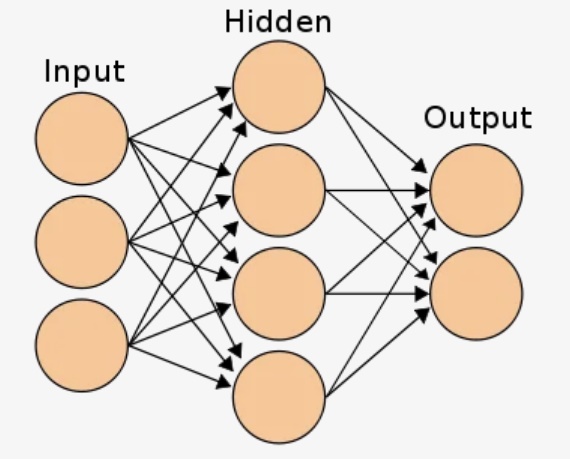 Объединив эти нейроны, вы получите в итоге прямо распространяющуюся нейронную сеть. В ней процесс идёт от ввода к выводу и через нейроны, которые соединены синапсами.
Объединив эти нейроны, вы получите в итоге прямо распространяющуюся нейронную сеть. В ней процесс идёт от ввода к выводу и через нейроны, которые соединены синапсами.
Для наилучшего понимания этого процесса посмотрите серию видео на английском, от Welch Labs.
Шаг 2. Сигмоида
Прежде чем приступить к следующему шагу, было бы неплохо ознакомиться с 4-й неделей курса по Machine Learning от Coursera — она как раз посвящена нейронным сетям и помогла бы вам разобраться в особенностях и принципах их работы. Да, этот курс слишком сильно углубляется в математику, плюс основан на Octave, хотя многие предпочитают Python. Но тем не менее там можно почерпнуть много полезных знаний.
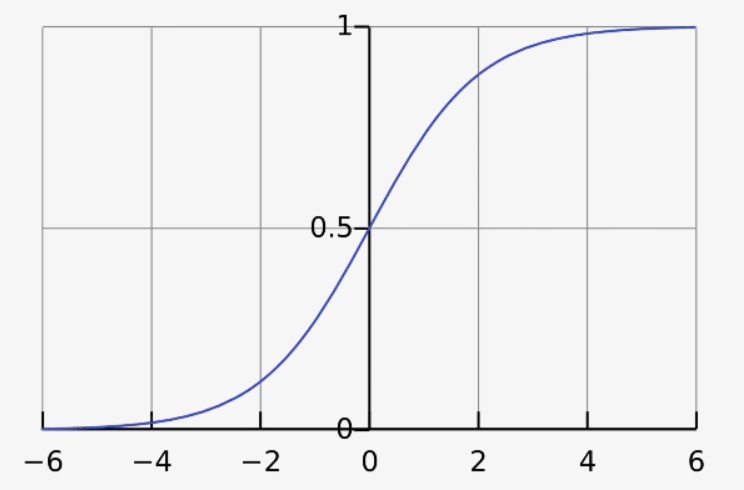 Итак, вернёмся к нашей сигмоиде. Дело в том, что она фигурирует во многих аспектах нейронных сетей. Её описание вы можете посмотреть, например, здесь. Но на одной теории, сами понимаете, далеко не уедешь. Именно поэтому для наилучшего понимания следует закодить её самостоятельно. Чтобы это сделать, следует написать реализацию алгоритма логистической регрессии, использующего сигмоиду.
Итак, вернёмся к нашей сигмоиде. Дело в том, что она фигурирует во многих аспектах нейронных сетей. Её описание вы можете посмотреть, например, здесь. Но на одной теории, сами понимаете, далеко не уедешь. Именно поэтому для наилучшего понимания следует закодить её самостоятельно. Чтобы это сделать, следует написать реализацию алгоритма логистической регрессии, использующего сигмоиду.
Если честно, это может занять целый день, причём результат будет далёк от идеального. Вот, к примеру, как с этим справился Per Harald Borgen, англоязычная статья которого стала основой материала, который вы сейчас читаете. Но главное здесь не в том, чтобы сделать всё идеально, а в том, чтобы разобраться, как всё работает. И понять, как устроена сигмоида.
Шаг 3. О методе обратного распространения ошибки
Понимание принципа работы нейронной сети, начиная от ввода, заканчивая выводом, вряд ли вызовет у вас затруднения. Намного тяжелее понять, каким образом нейронная сеть обучается, используя для этого наборы данных. Один из применяемых принципов называют методом обратного распространения ошибки.
Если говорить коротко, то вы оцениваете, насколько сильно ошиблась сеть, а потом изменяете вес входных значений (на первой картинке это синие числа).
Собственно говоря, процесс движется от конца к началу, ведь мы начинаем с конца сети и смотрим, как сильно догадка сети отклоняется от истины. При этом двигаемся назад, изменяя веса, и так до тех пор, пока не дойдём до ввода. А для вычисления всего этого вручную вам потребуется знание математического анализа. Однако вы можете на заморачиваться и использовать библиотеки, которые всё посчитают за вас.
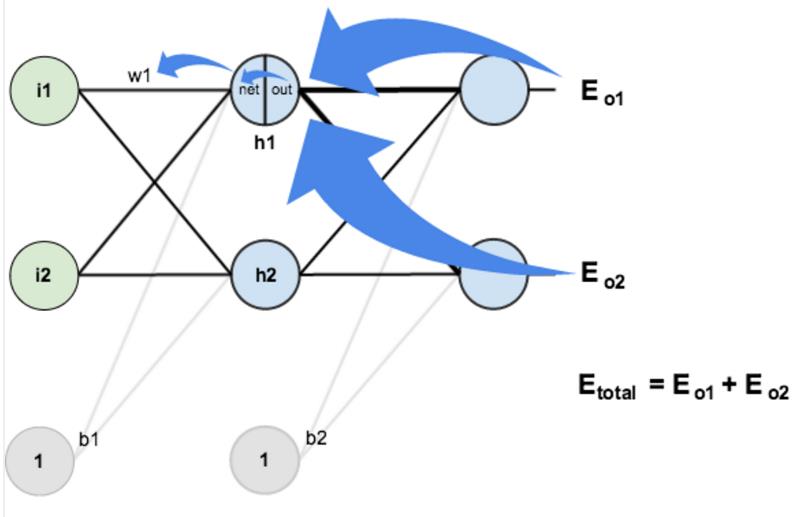 Если вас интересуют англоязычные источники, которые помогут разобраться в данном методе, то держите: • A Step by Step Backpropagation Example; • Hacker’s guide to Neural Networks; • Using neural nets to recognize handwritten digits.
Если вас интересуют англоязычные источники, которые помогут разобраться в данном методе, то держите: • A Step by Step Backpropagation Example; • Hacker’s guide to Neural Networks; • Using neural nets to recognize handwritten digits.
Однако учтите, что читая первые 2 статьи, вам обязательно придётся кодить самому, что поможет в дальнейшем. Избегать этого не рекомендуется, ведь в нейронных сетях невозможно разобраться, не практикуя. Что касается 3-й статьи, то это материал размером с книгу, больше напоминающую энциклопедию. Зато в ней даны подробные разъяснения важнейших принципов работы нейронных сетей. В частности, вы изучите функцию стоимости, градиентный спуск и т. д.
Шаг 4. Создание своей нейросети
Читая разные статьи и руководства, вы так или иначе будете создавать небольшие нейросети. И это очень эффективно для обучения в целом.
Пример очень полезной информации можно найти здесь. В этом материале удивительное количество знаний сжато до 11 строк кода.
 Прочитав вышеупомянутую статью и реализовав приведённые в ней примеры самостоятельно, вы закроете много пробелов в знаниях, а когда всё получится, почувствуете себя суперчеловеком)).
Прочитав вышеупомянутую статью и реализовав приведённые в ней примеры самостоятельно, вы закроете много пробелов в знаниях, а когда всё получится, почувствуете себя суперчеловеком)).
Что ещё? Ну, при реализации многих примеров используются векторные вычисления, поэтому понимание линейной алгебры тоже потребуется. Если же интересуют нейронные сети посложнее, то вот вам очередное руководство.
 С его помощью вы сможете как написать свою нейросеть, так и поэкспериментировать с уже созданными сетями. Довольно забавным бывает найти нужный набор данных, а потом проверить разные предположения с помощью нескольких сетей.
С его помощью вы сможете как написать свою нейросеть, так и поэкспериментировать с уже созданными сетями. Довольно забавным бывает найти нужный набор данных, а потом проверить разные предположения с помощью нескольких сетей.
Кстати, если интересуют хорошие наборы данных, вы можете посетить этот сайт.
Чем раньше вы начнёте свои эксперименты, тем лучше. Будет кстати и изучение Python-библиотек для программирования нейронных сетей: Theano, Lasagne, Nolearn. А ещё лучше — записаться на курс «Нейронные сети на Python» в OTUS. С его помощью вы освоите архитектуру нейронных сетей, узнаете методы их обучения и особенности реализации.
Как работает нейронная сеть: алгоритмы, обучение, функции активации и потери
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
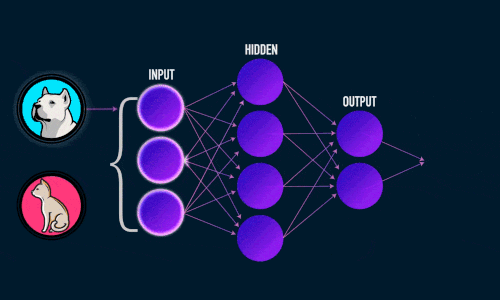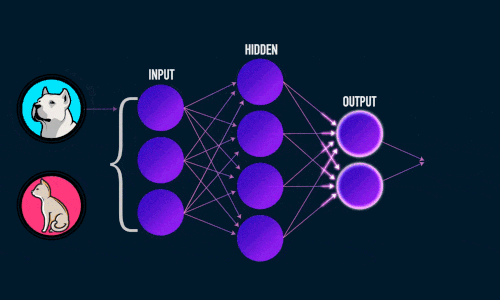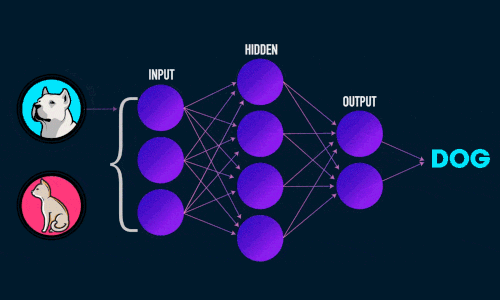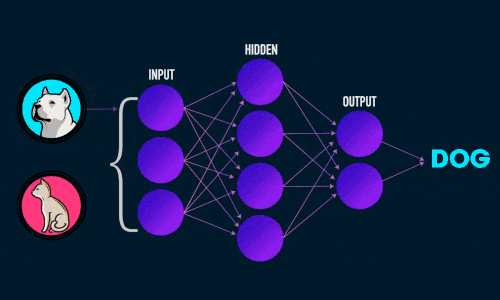
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
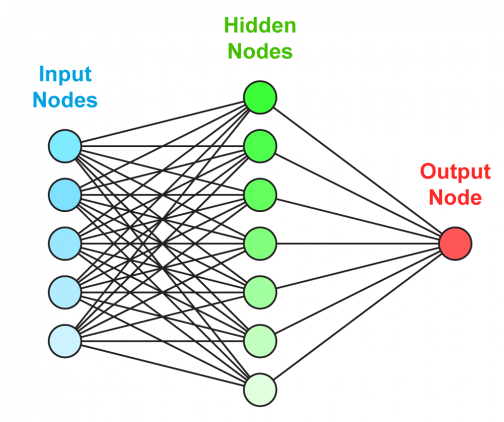
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
Прямое распространение ошибки
Зададим начальные веса случайным образом:
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
Обратное распространение
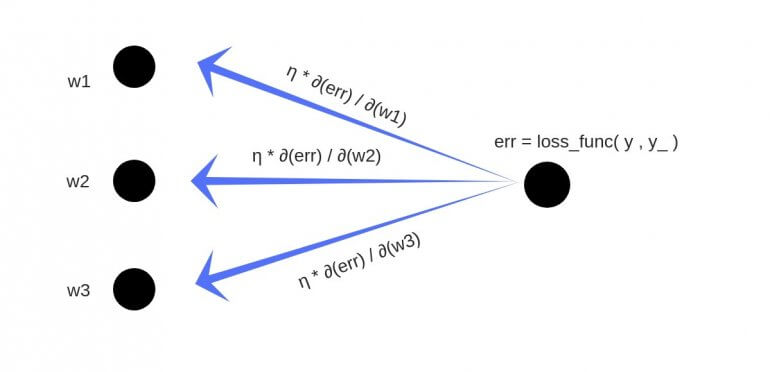
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.
 Популярный мем о том, как Карлсон стал Data Science разработчиком
Популярный мем о том, как Карлсон стал Data Science разработчиком
 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
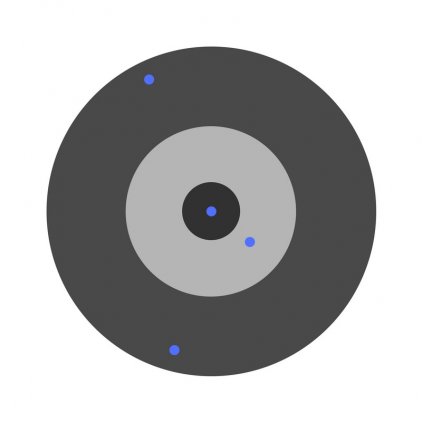
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
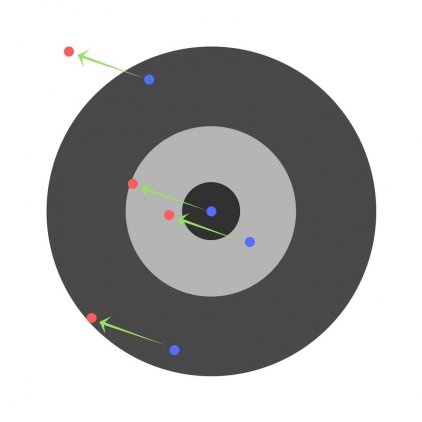
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
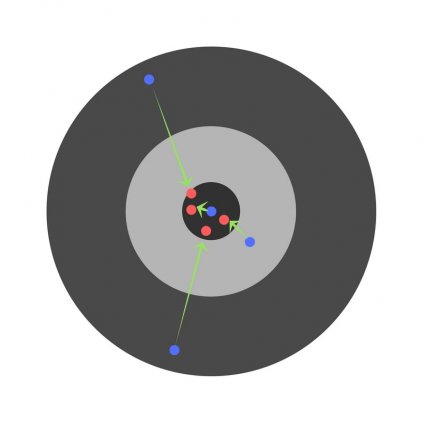
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
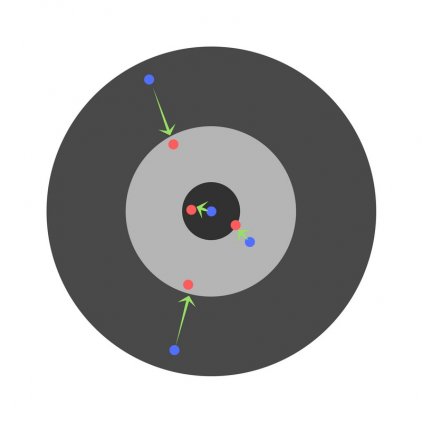
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
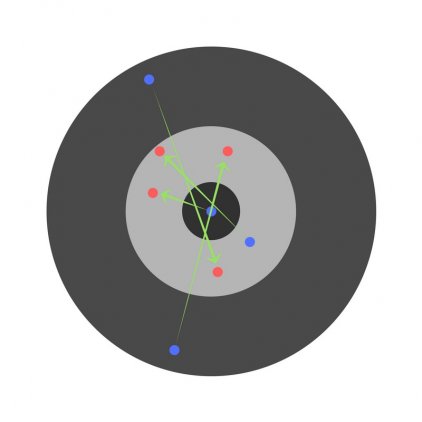
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
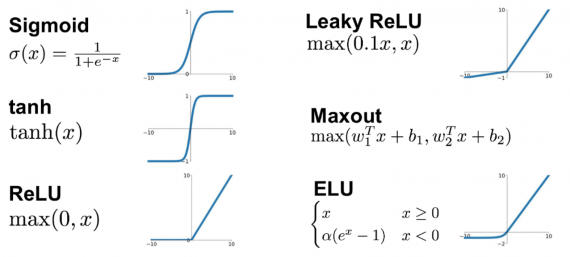
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
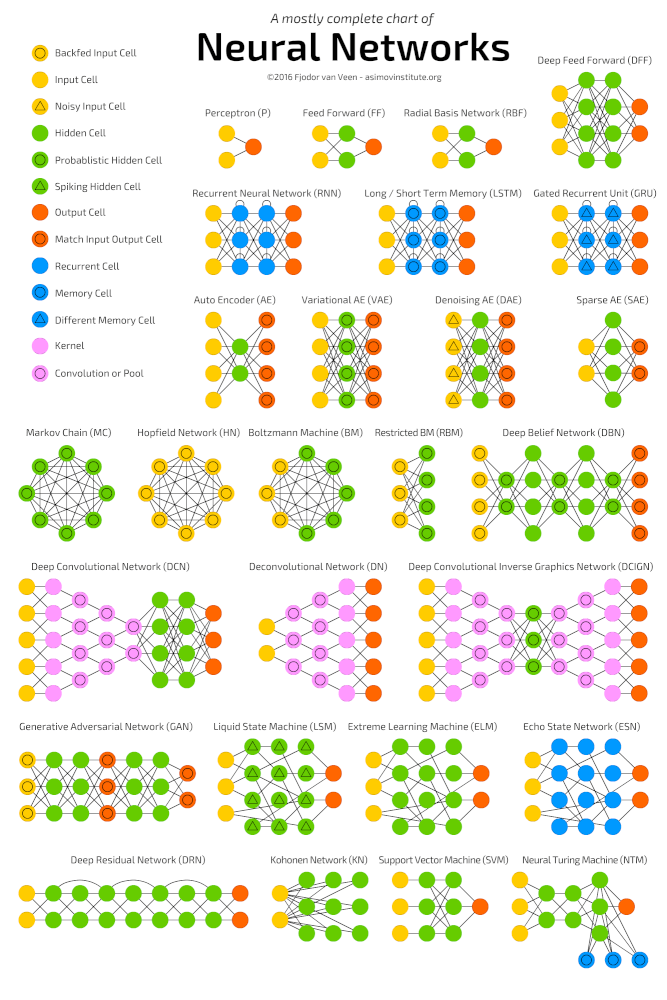 Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:
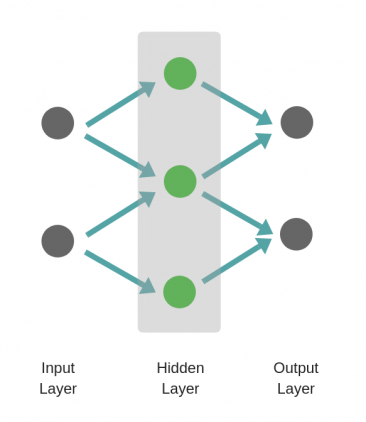
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
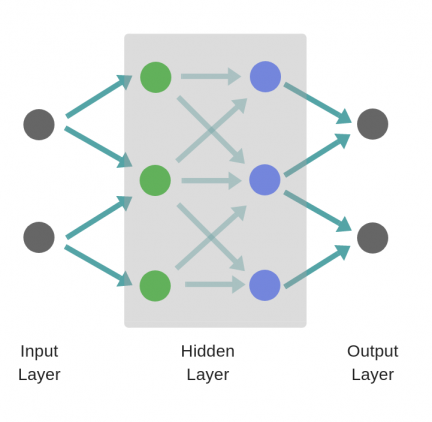
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
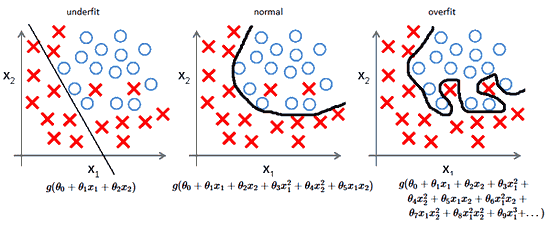
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.

